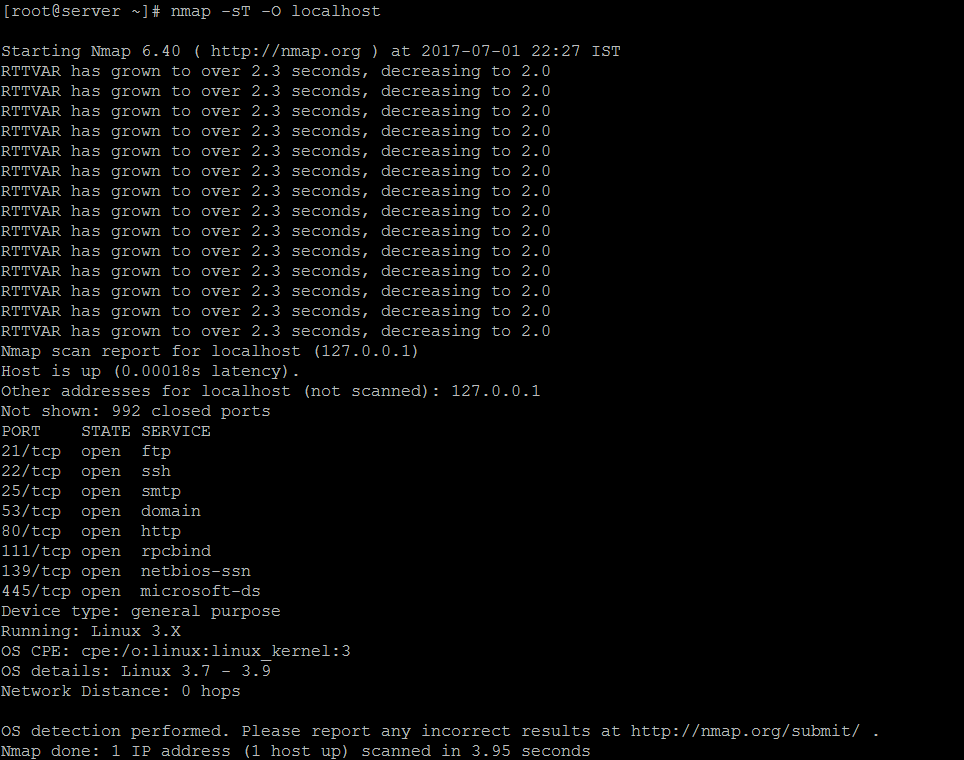
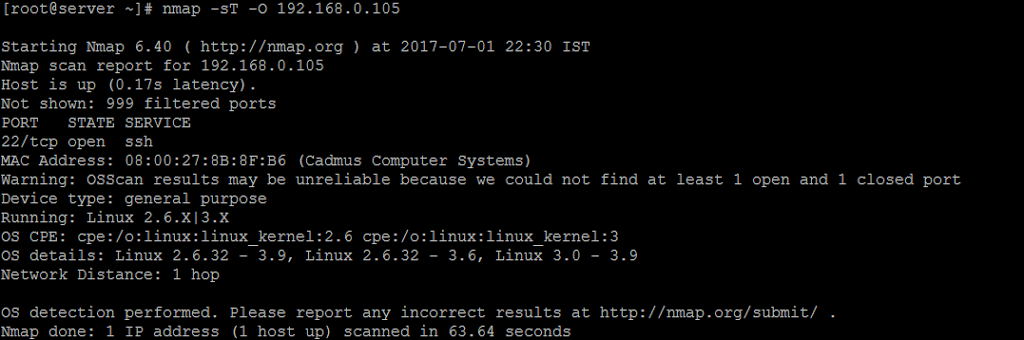
Domain Naming System is a naming convention for computers, which is connected to the internet. Its not possible to remember all the web server IP Address. So, here its comes as a resolution for this. Because, It will translate from the IP Address to Name and Name to IP Address.
We are going to see how to setup DNS in RHEL 7 and Cent OS 7.
Requirement:
Host Name: server.linuxbookcenter.com
IP Address: 192.168.43.226
Packages:
1. bind
2. bind-utils
Installing bind packages:
[root@server]# yum -y install bind*
BIND Configuring:
We are going to configure the “/etc/named.conf” file for BIND configuration.
open the file using vi editor and comment out two lines like shown below. This lines allow your DNS to listen all the IP Address.
Add your network by modifying “allow-query” line in the named.conf file to all the computers to do name transition which connected in this network
#vi /etc/named.conf
[root@server ~]# vi /etc/named.conf
options {
#listen-on port 53 { 127.0.0.1; };
#listen-on-v6 port 53 { ::1; };
directory "/var/named";
dump-file "/var/named/data/cache_dump.db";
statistics-file "/var/named/data/named_stats.txt";
memstatistics-file "/var/named/data/named_mem_stats.txt";
allow-query { localhost; 192.168.43.226/24;};
And the zone file information will be available in “/etc/named/rfc1912.zones” file by default. Here we should modify the entry based on our requirement.
Note: This entry contains the forward and reverse zone file names.
This file location included in “/etc/named.conf” file. Find the below screenshot.
Now save and exit from the “/etc/named.conf” file.
Provide zone file information entry:
edit the “/etc/named.rfc1912.zones” file to provide the zone file information entries.
[root@server ~]# vi /etc/named.rfc1912.zones
And make the below entries or modify the existing one based on our requirement.
zone "localhost.localdomain" IN {
type master;
file "named.localhost";
allow-update { none; };
};
zone "lbcdomain.com" IN {
type master;
file "fwd.lbcdomain.com.db";
allow-update { none; };
};
zone "1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.ip6.arpa" IN {
type master;
file "named.loopback";
allow-update { none; };
};
zone "1.0.0.127.in-addr.arpa" IN {
type master;
file "named.loopback";
allow-update { none; };
};
zone "226.43.168.192.in-addr.arpa" IN {
type master;
file "43.168.192.db";
allow-update { none; };
};
Create and Configure the Zone files:
Default location for the zone file’s : /var/named
create a forward zone file with “fwd.lbcdomain.com.db” name.
[root@server named]# vi /var/named/fwd.lbcdomain.com.db
Provide the below entries to complete the forward zone configuration.
keywords for Zone Files
A – A record
NS – Name Server
MX – Mail for Exchange
CN – Canonical Name
$TTL 86400
@ IN SOA server.lbcdomain.com. root.lbcdomain.com. (
20171129 ; serial
3600 ; refresh
1800 ; retry
604800 ; expire
86400 ) ; minimum
;Name server info
@ IN NS server.lbcdomain.com.
;Name server Ip info
server IN A 192.168.43.226
;Mail exchanger
lbcdomain.com. IN MX 10 mail.lbcdomain.com.
;A - Record Hostname to IP Address
www IN A 192.168.43.10
mail IN A 192.168.43.15
;CNAME Record
ftp IN CNAME www.lbcdomain.com.
Save and exit from the file and create reverse zone file with the name of “43.168.192.db”
PTR – Pointer
SOA – Start of Authority
[root@server ~]# vi /var/named/43.168.192.db
make the below entries in reverse zone file like below.
$TTL 86400
@ IN SOA server.lbcdomain.com. root.lbcdomain.com. (
20171129 ; serial
3600 ; refresh
1800 ; retry
604800 ; expire
86400 ) ; minimum
;Name server info
@ IN NS server.lbcdomain.com.
;Reverse lookup info
226 IN PTR server.lbcdomain.com.
;PTR Record for IP to Hostname
10 IN PTR www.lbcdomain.com.
15 IN PTR mail.lbcdomain.com.
Save and exit from the file.
We completed all the configuration and we should restart the bind service.
[root@server ~]# systemctl restart named
Make it enabled in system startup.
[root@server ~]# systemctl enable named
Now login in any client system which is already connected in same network and make DNS entries in
/etc/resolv.conf file like below.
#vi /etc/resov.conf
Save and exit from the file and if NM is managing the network, make DNS entry in /etc/sysconfig/network-scripts/ifcfg-eth0
Note: In my infra i took this network adapter configuration file for this ifcfg-eth0. This might vary in your systems.
#vi /etc/sysconfig/network-scripts/ifcfg-eth0
Save and exit after making the entry and restart the network service.
#service network restart
Will check the DNS connection from the client to DNS servers using dig command. Use the below command to check forward lookup
#dig www.lbcomain.com
Will receive the below output if working good.
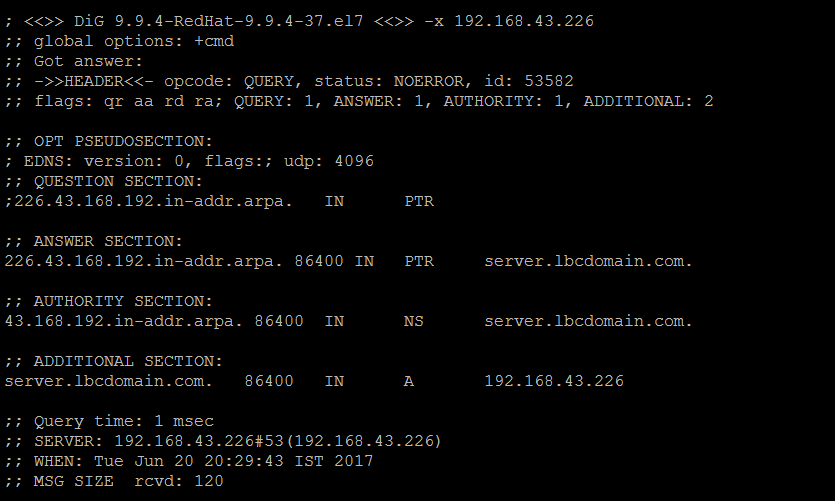
Check in reverse from IP to Hostname to confirm whether the reverse lookup is working fine not.
#dig -x 192.168.43.226
Output:
We completely done on DNS configuration now:)